Gemini TTS Extension
Documentation for Text-to-Speech Functions
Developed by: Mr.Koder (AKA _Ahmed)
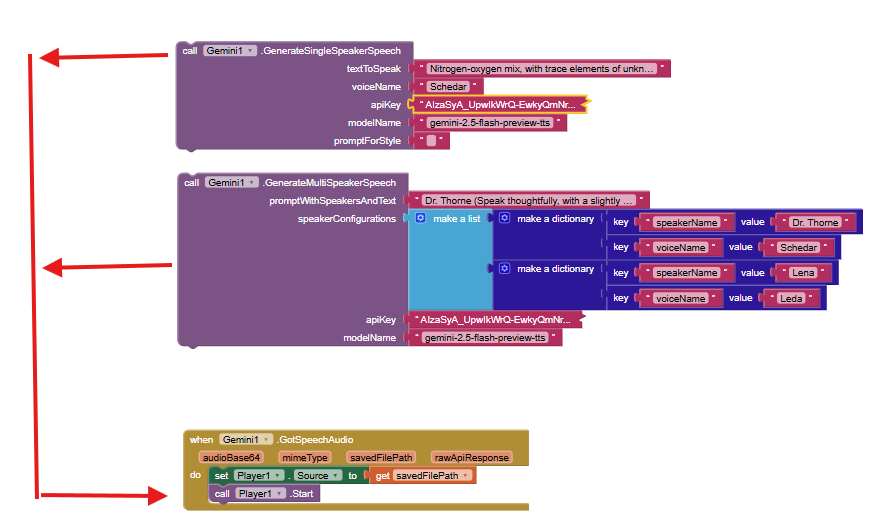
GenerateSingleSpeakerSpeech
This function generates speech from text using a single specified voice. You can provide style instructions directly within the prompt.
Parameters:
| Parameter | Type | Description | Example / Notes |
|---|---|---|---|
| textToSpeak | Text | The plain text to be converted to speech if promptForStyle is empty. |
"Hello world." |
| voiceName | Text | The desired voice from the Gemini API's list. See 'Available Voices' section below. | "Kore", "Puck" |
| apiKey | Text | Your Google Gemini API Key. | "AIzaSy..." |
| modelName | Text | The specific Gemini TTS model to use. | "gemini-2.5-flash-preview-tts" or "gemini-2.5-pro-preview-tts" |
| promptForStyle | Text | The full utterance including any style instructions. If provided, textToSpeak is ignored. |
"Say this very excitedly: This is amazing!" |
promptForStyle vs textToSpeak:
If promptForStyle is NOT empty, its content will be sent to the API, and textToSpeak will be ignored.
The API will interpret style instructions (e.g., "Speak calmly:") and the subsequent text from the promptForStyle value.
GenerateMultiSpeakerSpeech
Generates speech for a conversation involving multiple speakers, each potentially with a different voice. The API currently supports exactly TWO distinct speakers for this function.
Parameters:
| Parameter | Type | Description | Example / Notes |
|---|---|---|---|
| promptWithSpeakersAndText | Text | The full dialogue, clearly indicating speaker names. Style prompts can be embedded. | "Alice (Sounding curious): Hello Bob. Bob (Cheerfully): Hi Alice!" |
| speakerConfigurations | List of Dictionaries | A list configuring each speaker. Each dictionary must have "speakerName" (matching the prompt) and "voiceName".
[Show Details]
|
See details below. Max 2 unique speakers. |
| apiKey | Text | Your Google Gemini API Key. | "AIzaSy..." |
| modelName | Text | The specific Gemini TTS model to use. | "gemini-2.5-flash-preview-tts" or "gemini-2.5-pro-preview-tts" |
Details for speakerConfigurations:
This must be an App Inventor list where each item is a dictionary. Each dictionary defines one speaker:
- Key:
"speakerName"(Text) - Must exactly match a speaker name used in yourpromptWithSpeakersAndText(e.g., "Alice", "Bob"). Case-sensitive. - Key:
"voiceName"(Text) - The Gemini API voice to use for this speaker (e.g., "Kore", "Puck").
App Inventor Block Example:
Create SpeakerConfigurations List
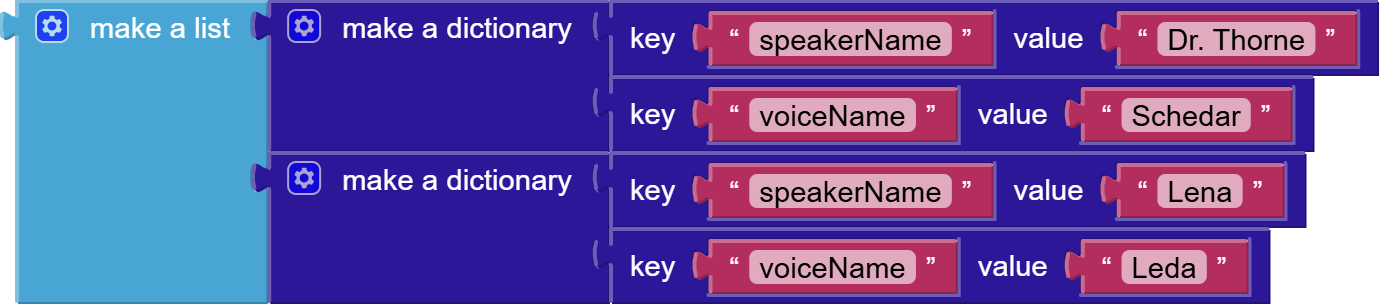
multi_speaker_voice_config. If you provide configurations for more than two unique speakers, you will receive an API error.
Handling Events
After calling either speech generation function, one of the following events will be triggered.
GotSpeechAudio
Triggered upon successful speech generation and file saving.
| Parameter | Type | Description |
|---|---|---|
| audioBase64 | Text | The generated audio data encoded as a Base64 string. Can be very large. |
| mimeType | Text | The actual MIME type of the audio data as reported by the Gemini API (e.g., "audio/wav", "audio/mpeg"). |
| savedFilePath | Text | The absolute path to the audio file saved on the device (e.g., in ASD or cache). Use this path with the App Inventor Player component. |
| rawApiResponse | Text | The full, raw JSON response from the Gemini API. Useful for debugging. |
Playing the Audio
SpeechGenerationError
Triggered if an error occurs during the speech generation process (API error, network issue, file saving error, etc.).
| Parameter | Type | Description |
|---|---|---|
| errorMessage | Text | A message describing the error. This may include details from the Gemini API. |
Handling an Error
When Gemini.SpeechGenerationError
errorMessage = [get errorMessage]
Do
Notifier1.ShowAlert (notice = "TTS Error: " + [get errorMessage])
Basic Usage Flow
savedFilePath
Important Notes & Best Practices
- API Key: Keep your Gemini API Key secure. Do not embed it directly in publicly shared AIA files if possible.
- Model Names: Use
"gemini-2.5-flash-preview-tts"(faster, good for general use) or"gemini-2.5-pro-preview-tts"(potentially higher quality). These are "Preview" models, so their availability or features might change. - Output File: The extension attempts to create a playable
.wavfile. If the API returns MP3 data (mimeTypewill be"audio/mpeg"), the file will be saved as.mp3. - Permissions: Your App Inventor app will need INTERNET permission. No special file permissions are usually required for the extension to save to its private app-specific directory (ASD) or cache.
- Error Messages: Pay close attention to the
errorMessagefrom theSpeechGenerationErrorevent. It often contains specific details from the Gemini API that can help you debug issues with your prompts or API key. - Rate Limits: Be mindful of Gemini API rate limits. Making too many requests in a short period might lead to temporary blocks.
Available Voices (voiceName parameter)
The Gemini TTS API supports a variety of voices. Use one of the following names for the voiceName parameter:
- Zephyr
- Puck
- Charon
- Kore
- Fenrir
- Leda
- Orus
- Aoede
- Callirhoe
- Autonoe
- Enceladus
- Iapetus
- Umbriel
- Algieba
- Despina
- Erinome
- Algenib
- Rasalgethi
- Laomedeia
- Achernar
- Alnilam
- Schedar
- Gacrux
- Pulcherrima
- Achird
- Zubenelgenubi
- Vindemiatrix
- Sadachbia
- Sadaltager
- Sulafar
You can test these voices in Google AI Studio.